Сайзинг при развёртывании Exchange 2013
1. Для начала общая картина
Как правило, данные для предоставления рекомендаций по сайзингу представляют собой результаты многочисленных тестов, выполненных на ранних стадиях разработки продукта. Затем эти данные прорабатываются, чтобы данные в руководстве по установке и работе продукта были наиболее близкими к финальному релизу. Развёртывание Exchange на производстве началось с Exchange Dogfood (здесь имеется в виду копии Exchange, предварительно установленные для внутренних потребностей команды по разработке Exchange и других групп сотрудников компании Microsoft), корпоративного внедрения Exchange в IT-сферу компании Microsoft и в различные программы, в которые обычно внедряют технологические новинки.
Данная статья, посвящённая по сайзингу Exchange 2013, прежде всего, основана на этой информации о наблюдениях за развёртыванием Exchange Dogfood. На Dogfood содержатся наиболее требовательные из пользователей компании Microsoft - сотрудники, которые передают огромное количество сообщений и сотрудники, каждый из которых поддерживает большое количество клиентских сеансов для множества типов клиентов. Многие пользователи Dogfood, отправляют и получают более 500 сообщений ежедневно и, обычно, имеют множество клиентов Outlook, а также множество подключённых, активных мобильных устройств, работающих одновременно. Это позволяет данной статье быть в некоторой степени консервативной, принимающей во внимание дополнительные расходы со стороны типов клиентов, которые не встречаются нам регулярно при развёртываниях внутри компании, так же, как и особенности клиентов, которые могут отличаться от того, что считается «нормальным» в компании Microsoft.
Значит ли это, что вам следует использовать данную "консервативную" статью и прислушиваться к рекомендациям, таким как разворачивание меньшего количества оборудования? Абсолютно, нет. Одна из многих возможностей, которую можно извлечь из работы с данным крупномасштабным сервисом – это его доступность и надёжность, которые сильно зависят от наличия возможности преодоления неожиданных максимальных нагрузок.
Сайзинг – это одновременно и наука, и искусство. Попытка сделать процесс сайзинга слишком научным (то есть попытка сделать его очень точным), как правило, приводит к недостатку дополнительных возможностей для преодоления максимальных нагрузок, что, в конечном счёте, приводит к недовольству пользователей и снижению доступности системы. С другой стороны, при сайзинге должен быть использован научный подход, иначе будет очень сложно получить предсказуемую и воспроизводимую методологию по расчёту потребных вычислительных мощностей в будущем.
2. Влияние новой архитектуры
С точки зрения сайзинга и производительности, существует множество преимуществ новой архитектуры Exchange 2013. Exchange 2010, объединяющий роли Mailbox, Hub Transport и Client Access Server (CAS) в одном сервере, - отличный способ получить отдачу от аппаратных ресурсов современных серверов и упростить процессы планирования вычислительных мощностей и развёртывания. Данные преимущества также применимы к инсталляции Exchange 2013 в роли почтового сервера. Считается, что сервисы, работающие на сервере роли Mailbox, обеспечивают сбалансированное использование ресурсов, вместо того, чтобы иметь ряд сервисов, работа которых сильно загрузит диск и процессор.
Другая особенность почтового сервера роли Mailbox – эффективное использование кэша. Разработчики программного обеспечения используют кэширование в памяти, чтобы не извлекать данные методами, требующими продолжительного времени ожидания (такие, как запросы LDAP, RPC или чтение с диска). В архитектурах Exchange 2007 и 2010 обработка операций, связанных с конкретным пользователем, может происходить на нескольких серверах по всей топологии. Один CAS (Client Access Server) конкретного пользователя обрабатывает Outlook Web App, тогда как другой (возможно, больше, чем один) CAS обрабатывает соединения Exchange ActiveSync, остальные CAS обрабатывают соединения RPC-прокси Outlook Anywhere RPC для того же пользователя. Возможно даже, что набор серверов, обрабатывающих данную нагрузку, может регулярно меняться. То есть любые хранящиеся в кэше данные, которые ассоциируются с пользователем, становятся бесполезными (потеря памяти) как только эти соединения будут перенаправлены на другие сервера. В архитектуре Exchange 2013 вся работа, выполняющаяся для конкретного пользователя, происходит на почтовом сервере, размещающим активную копию почтового ящика этого пользователя, поэтому кэш используется намного эффективней.
Новая роль CAS даёт ряд замечательных преимуществ. Учитывая то, что она не меняет состояние с пользовательской точки зрения, её можно легко масштабировать согласно требованиям, добавляя или убирая серверы из топологии. По сравнению с ролью CAS в прошлых релизах, значительно уменьшилось использование аппаратных ресурсов, что означает уменьшение необходимого количество машин, требуемых для выполнения данной роли. Кроме того, для многих клиентов имеет смысл обратить внимание на многоцелевое развёртывание, при котором сервера CAS и Mailbox располагаются вместе – это позволяет ещё больше упростить процессы подбора вычислительных мощностей и развёртывания, а также увеличить число доступных CAS, что увеличит доступность услуг.
2.1 От начала до конца, что представляет собой процесс сайзинга?
Сайзинг Exchange состоит из шести основных этапов. В данной статье подробно остановимся на каждом из них:
- Убедитесь, что вы полностью понимаете информацию, содержащуюся в данной статье, перед началом сайзинга. Для начала, прочтите её. Это будет отличным стартом!
- Второй этап – сбор любой доступной информации по уже развёрнутой системе обмена сообщениями (если таковая имеется) или оценка требований пользовательского профиля, если это абсолютно новое решение.
- Третий этап, возможно, самый трудный. Вам необходимо выяснить все требования для корректной работы решения Exchange, которые могут повлиять на процесс сайзинга. Например, желаемый объём почтового ящика (квота почтового ящика), требования к уровню сервисного обслуживания, количество точек установки, количество копий базы данных почтового ящика, архитектура памяти, планы по расширению, развёртывание сторонних продуктов или производственных прикладных систем и т.д. В конечном итоге вам надо определить те аспекты архитектуры, которые могут повлиять на количество серверов, количество пользователей и загрузку серверов.
- Как только вы получите список всех требований, ограничений, и данные о профиле пользователя – пора вычислять требования Exchange. Самый лёгкий способ сделать это – воспользоваться калькулятором требований для роли сервера почтовых ящиков, но вычислить требования можно также и вручную. О том, как именно это можно сделать, читайте дальше в статье. Понятно, что калькулятор значительно облегчает процесс вычислений. Поэтому, если он доступен, используйте его!
- После вычисления требований Exchange, рассмотрите различные доступные варианты. Например, может встать выбор между вертикальным (развёртыванием меньшего количества крупных серверов) и горизонтальным масштабированиями (развёртыванием большого количества меньших серверов). Выбор того или иного варианта повлияет как на обеспечение высокой доступности, так и на общее число сбоев аппаратных и программных средств, которые Exchange сможет выдержать, оставаясь доступным для пользователей. Другое типичное решение связано с архитектурой будущего хранилища и часто упирается в его стоимость. Существуют различные варианты хранилищ в разных ценовых категориях, каждое со своими преимуществами, и требования Exchange часто могут быть удовлетворены различными вариантами хранилищ.
- Последний этап – завершение дизайна. На данном этапе вы должны задокументировать все принятые решения, упорядочить некоторое аппаратное оборудование, воспользоваться программным средством Jetstress для подтверждения того, что требования к хранилищу могут быть удовлетворены, и выполнить любые другие лабораторные испытания, чтобы гарантировать, что внедрение в промышленную эксплуатацию пройдёт гладко.
3. Сбор требований и пользовательских данных
Основным источником информации для проведения всех последующих вычислений является развёртывание среднего пользовательского профиля, где пользовательский профиль определён как среднее значение общего количества отправленных и полученных каждым пользователем сообщений в течение каждого рабочего дня. Во многих организациях пользовательские профили мало чем отличаются. Например, одна группа пользователей может быть обозначена как «сотрудники, работающие с информацией» и тратить большую часть своего рабочего времени на отправку и чтение сообщений из почтового ящика, в то время как другая группа пользователей может фокусироваться на решении других задач и редко пользоваться электронной почтой. Сайзинг для данных групп пользователей может быть выполнен путём рассмотрения системы в целом, используя средневзвешенные значения, или разделяя процесс сайзинга для согласования с каждой из групп пользователей. Вообще говоря, гораздо легче провести вычисления для всей системы, приняв её за единое целое, но могут возникнуть определённые требования (например, использование некоторых сторонних инструментов или устройств), которые в значительной степени повлияют на сайзинг для одной или более групп пользователей. Применение факторов сайзинга к данной группе пользователей в попытке провести вычисления для всей системы, приняв её за единое целое, может вызвать значительные трудности.
Очевидный вопрос, который может у вас возникнуть – как получить информацию о пользовательском профиле? Если у вас уже развёрнуто решение Exchange, то существует ряд возможностей, которыми вы можете воспользоваться, при условии, что вы не являетесь неуловимым администратором Exchange, который и так отслеживает подобную статистику на постоянной основе. Если вы работаете с Exchange версии 2007 или более ранней, вы можете воспользоваться инструментом Exchange Profile Analyzer (EPA), который предоставит вам как полную статистику по пользовательскому профилю для организации работы Exchange, так и статистику по каждому пользователю, если это требуется. Если вы работаете с Exchange 2010, то в данном случае EPA не подходит. Одним из возможных вариантов является оценка трафика сообщений, используя счётчики производительности, для получения приблизительных средних значений пользовательского профиля для каждого сервера. Это может быть выполнено путём мониторинга счётчиков MSExchangeIS\Messages Submitted/sec и MSExchangeIS\Messages Delivered/sec во время средних пиковых периодов, и экстраполяции полученных данных для ежедневного отображения средних значений по каждому пользователю. Другим вариантом является использование протоколов отслеживания сообщений для генерации данной статистики. Эта задача может быть выполнена с помощью скриптов PowerShell. Вы можете написать свой скрипт или найти готовый.
Типичные пользовательские профили попадают в диапазон от 50 до 500 отправляемых/получаемых сообщений на каждого пользователя ежедневно, поэтому в данной статье приведены рекомендации для данного диапазона профилей. Если сомневаетесь, округляйте в большую сторону.

Другой важной информацией о профиле, необходимой для сайзинга, является средний размер сообщений, встречаемых при развёртывании. Эти данные могут быть получены с помощью EPA или другими приведёнными здесь методами (с помощью счётчиков производительности передачи или протоколов отслеживания сообщений). Например, в компании Microsoft средний размер сообщения обычно составляет приблизительно 75 KB, но они, конечно же, работают и с пользователями, которые имеют гораздо больший размер сообщений. Размер сообщений в значительной степени зависит от индустрии и региона.
4. Серверы почтовых ящиков
Рекомендуется начать сайзинг для Exchange 2013 с серверов роли Mailbox. На самом деле те из вас, кто развёртывал Exchange 2010, найдут много общего с приведённой здесь методологией.
4.1 Пример сценария
В этой статье все вычисления проведём для следующего примера развёртывания. Развёртывание проводится для относительно большой организации со следующими характеристиками:
-
100 000 почтовых ящиков;
-
профиль – 200 сообщений/день, средний размер сообщений составляет 75 KB;
-
квота почтового ящика – 10GB;
-
единственная площадка установки;
-
4 не изолированные копии базы данных почтового ящика;
-
2U типовые серверные платформы с внутренними дисковыми полками и внешним хранилищем (всего доступно 24 отсека большого форм-фактора);
-
используются средние по производительности диски SAS 4TB, 7200 оборотов;
-
базы данных почтовых ящиков хранятся на JBOD – последовательно подключаемой системе хранения данных (не использую RAID);
-
решение должно обладать двойной отказоустойчивостью.
4.2 Модель высокой доступности
Первое, что вам необходимо определить – используемую модель высокой доступности (high availability model), то есть, каким образом вы сможете удовлетворить требования доступности, определённые ранее. Решение, вероятно, будет состоять во множественном копировании баз данных в одну или более Database Availability Groups (DAG), что повлияет на объём хранилища и требования IOPS.
Как минимум, вам необходимо ответить на следующие вопросы:
-
Будете ли вы развёртывать несколько копий базы данных?
-
Сколько копий базы данных вы собираетесь развернуть?
-
Предусматриваете ли вы использование архитектуры, которая обеспечит отказоустойчивость установки?
-
Какая модель отказоустойчивости будет применена?
-
Каким образом вы распределите копии баз данных?
-
Какую архитектуру хранилища вы будете использовать?
4.3 Требования к хранимому объёму данных
После того, как вы определитесь, каким образом вы удовлетворите требования высокой доступности, вам необходимо узнать количество копий баз данных и площадок, которые будут развёрнуты. Учитывая эту цифру, вы можете начинать оценивать требования по объёму хранимых данных. На базовом уровне объём хранимых данных можно определить как сумму объёмов, требуемых для хранения данных почтовых ящиков (в первую очередь этот параметр основан на квоте дискового пространства, выделяемой почтовому ящику), объём данных для файлов протоколов базы данных, объём данных для файлов индексации, и дополнительный объём для расширения в будущем. Каждая копия базы данных почтового ящика является множителем поверх основных требований к хранилищу. Рассмотрим упрощённый пример: при создании 500 почтовых ящиков по 1GB каждый, объём хранимых данных всех почтовых ящиков составил бы 500GB; затем необходимо учесть различные факторы, значения которых определяют требования для каждой копии хранилища. Отсюда, если, например, мне необходимо создать 3 копии данных для обеспечения высокой доступности, я должен умножить данную цифру на 3, чтобы получить суммарную требуемую ёмкость системы хранения для выбранного решения (всех серверов). На самом деле, как вы увидите далее, требования к хранению данных для Exchange 2013 более комплексные.
4.3.1 Размер почтового ящика
Для определения реального размера почтового ящика на диске, необходимо рассмотреть три характеристики: квота почтового ящика, свободное пространство базы данных, и элементы для восстановления (recoverable items).
Под квотой почтового ящика большинство людей понимает его «размер», представляющий собой максимальное количество данных, которое пользователь может хранить в своём почтовом ящике на сервере. В то время как, разумеется, квота почтового ящика представляет собой большую часть пространства, используемого базами данных Exchange. Это не единственный элемент, посредством которого необходимо проводить сайзинг.
Свободное пространство базы данных – это объём пространства файла базы данных почтового ящика, выделенного на диске, но не содержащего ни одной используемой страницы базы данных. Необходимо рассматривать его как свободное пространство для записи новых данных. После удаления содержимого почтовых ящиков из баз данных, а затем и из элементов почтового ящика для восстановления, страницы базы данных, которые содержали удалённый контент, становятся частью свободного пространства.

Это означает, что пользователь, имеющий профиль в 200 сообщений/день и средний размер сообщений 75KB, будет использовать следующий объём свободного пространства:
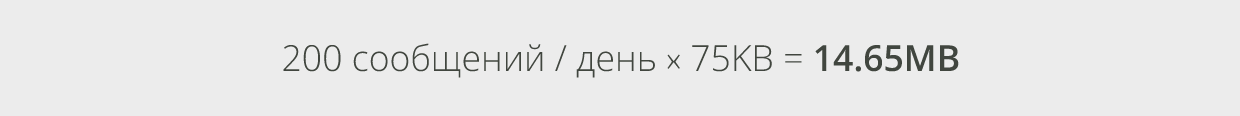
При удалении писем из почтового ящика, они, фактически, не удаляются, а временно перемещаются в папку recoverable items – папку для восстановления, откуда могут быть восстановлены в течение некоторого периода. Также, как и Exchange 2010, Exchange 2013 обладает свойством, называемым «восстановление отдельных элементов», которое предотвращает очистку данных из папки для восстановления в течение некоторого времени. Когда это свойство активно, ожидается увеличение размера почтового ящика примерно на 1,2% на протяжении срока сохранения удалённых сообщений, который обычно составляет 14 дней. Кроме того, ожидается увеличение размера почтового ящика на 3% для календарной регистрации версии писем, которая по умолчанию является активной. Учитывая это, почтовый ящик, в конечном счёте, достигнет устойчивого состояния, при котором количество нового контента приблизительно будет равно количеству удаляемого контента, чтобы не превышать отведённую ему квоту. То есть, ожидается, что размер элементов почтового ящика в папке recoverable items, со временем, будет равен размеру отправляемых и получаемых сообщений в течение срока хранения удалённых элементов. То есть наибольший размер папки recoverable items может быть вычислен следующим образом:

Подставив в формулу данные из нашего примера, где профиль пользователя составляет 200 сообщений/день, средний размер сообщений равен 75 KB, срок хранения удалённых элементов составляет 14 дней, а квота почтового ящика равна 10GB, ожидаемый размер папки для восстановления будет равен:

Приняв во внимание результаты проведённых вычислений, выведем коэффициенты использования ёмкости системы хранения для почтового ящика, чтобы рассчитать предполагаемый размер почтового ящика на диске:
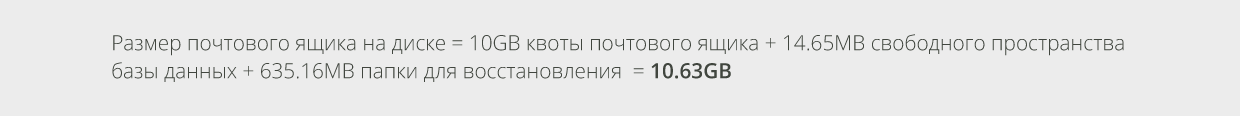
4.3.2 Индексация контента
Объём памяти, требуемый для файлов, необходимых для процесса индексации контента, может быть приблизительно подсчитан как 20% от размера базы данных:

Кроме того, необходимо провести расчёты ещё для одного дополнительного индекса контента (например, составляющий 20% от одной из баз данных почтового ящика на томе), чтобы обеспечить окончательное выполнение задач по индексации контента (в частности, для процесса слияния). Лучший способ изобразить необходимость в требованиях к основному объединению пространства – посмотреть на средний размер файла базы данных на томе и добавить к расчётам один объём, занимаемый базой данных на диске. Тогда, расчёт для каждого тома объёма памяти, требуемого для индексации контента, будет выглядеть следующим образом:

Например, если имеется 2 базы данных почтового ящика на одном томе и каждая база данных занимает 100GB пространства тома, можно рассчитать объём памяти, требуемый для индексации контента, как:
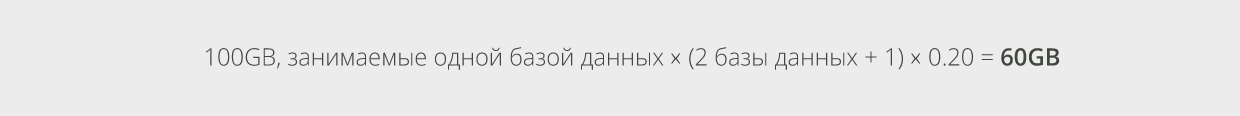
4.3.3 Место для логов
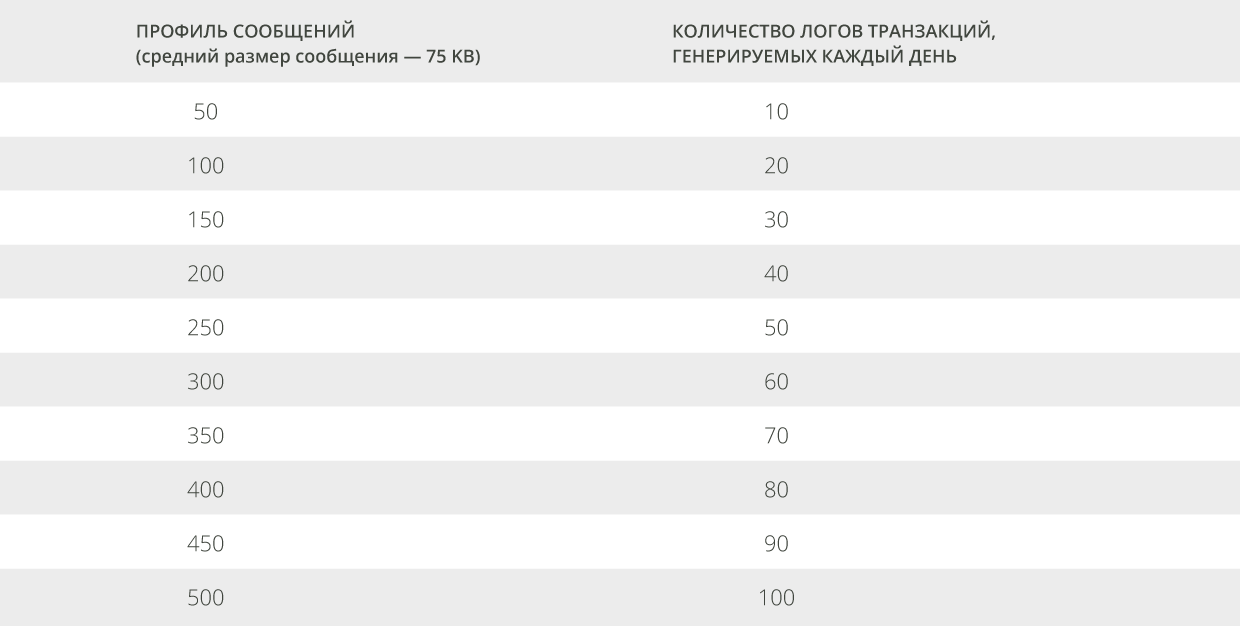
Объём хранилища, требуемый для журналов транзакций расширенного обработчика событий (англ. Extensible Storage Engine или ESE), может быть вычислен так же, как и для Exchange 2010. В общем, процесс расчёта выглядит так: во-первых, вы должны определить базовый критерий - количество ежедневно генерируемых пользователем лог-транзакций, используя таблицу 1. Как и в Exchange 2010, файлы логов имеют размер 1MB, что делает расчёт необходимого объёма данных для протоколов, довольно простым.
 |
|
| Таблица 1. Количество логов транзакций, генерируемых каждый день в соответсвии с профилем сообщений |
Как только вы выберете соответствующее значение из таблицы, в которой содержатся данные для среднего размера сообщения, равного 75 KB, вы должны привести его в соответствие с имеющимся у вас значением среднего размера сообщений. Каждый раз, когда вы удваиваете значение среднего размера сообщений, вы должны умножить количество логов транзакций, генерируемых каждый день, на коэффициент 1,9. Например:


Нам интересно количество логов транзакций, но данная цифра не отображает всего объёма хранения, требуемого для протоколов. Если используются традиционные резервные копии, то лог-файлы будут находиться на диске в интервале между полными резервными копиями. При перемещении почтовых ящиков изменения целевой базы данных приведут к значительному увеличению количества логов транзакций, производимых в течение дня. В качестве решения Exchange использует локальную защиту данных (например, вы не используете традиционное резервное копирование), при которой лог-файлы не будут урезаны при повреждении копии базы данных почтового ящика, или если весь сервер станет недоступным пока администратор не исправит данную ситуацию. Существует целый ряд факторов, которые необходимо учесть при подборе ёмкости хранения, требуемой для протоколов. Обратимся вновь к рассмотренному нами примеру. Рассчитаем требуемое лог-пространство для каждой базы данных, приняв число пользователей базы данных, равным 65. Примем также, что 1% пользователей перемещают раз в неделю, и что выделяется объём хранилища, достаточный для поддержки трёхдневных логов транзакций в случае повреждения копий баз данных или сбоев на серверах.



4.3.4 Объединение требований к объёмам хранения
Самый простой способ определения необходимого объёма дискового пространства без помощи доступного калькулятора – предположить, какой сервер и хранилище будут использованы. Рекмендуются 2U серверные платформы с ~12 отсеками большого форм-фактора в корпусах. Это позволит поставить 2 диска в RAID для операционной системы, установки Exchange, базы данных очереди транспортировки, и других служебных файлов, и использовать ~10 оставшихся дисков в качестве хранилища базы данных почтовых ящиков в конфигурации системы хранения данных с прямым подключением JBOD без применения RAID. Поместите в сервер 4TB SATA или midline диски SAS, и получите превосходный сервер Exchange 2013. Если вам необходим больший объём хранилища, добавьте дополнительную дисковую полку.
Используя пример большого развёртывания, и продумывая, каким образом можно было бы подобрать оборудование для серверной платформы, рассмотрите вариант масштабируемого сервера, содержащего 24 отсека большого форм-фактора, в которые помещены диски SAS среднего уровня общим объёмом 4 TB. Отведём 2 диска под ОС и Exchange, а остальные диски используем под нужды баз данных почтовых ящиков Exchange. Например, отведём 12 дисковых отсеков под базы данных, и оставим 10 отсеков пустыми или установим в них резервные диски. В качестве упражнения предположим, что на каждом диске будет находиться по 4 базы данных. После форматирования, каждый из дисков имеет ёмкость ~3725GB. Первым шагом для вычисления количества почтовых ящиков в базе данных является внимательное изучение таких характеристик, как полная требуемая производительность для баз данных, индексы контента и необходимое свободное пространство (которое мы примем равным 5%).
Для расчёта максимального объёма дискового пространства, доступного для почтовых ящиков, используем следующую формулу (обратите внимание, что в ней не учитывается дисковое пространство для лог-файлов – далее в процессе расчётов убедимся, что у нас будет достаточный объём хранения для этих файлов). Во-первых, вычтем требуемое свободное пространство из доступного объёма на диске:

Затем вычтем объём дискового пространства, необходимый для индексации контента. Как уже говорилось выше, объём дискового пространства, требуемый для индексации содержимого, составляет 20% от размера базы данных, и ещё дополнительные 20% размера одной базы данных на выполнение задач по техническому обслуживанию процесса индексации контента. Учитывая эти дополнительные требуемые 20%, можно вычислить общие требования к объёму дискового пространства просто как 20% от оставшегося объёма на томе. Вместо этого необходимо вычислить новый процент, который учтёт количество баз данных на каждом томе.

Теперь вычтем объём дискового пространства для индексации контента из полученного объёма памяти на томе:
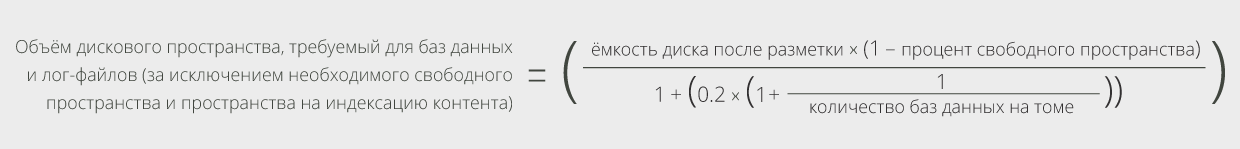
Затем, для вычисления максимального размера базы данных, разделим полученное значение на число баз данных на томе:

Для нашего примера получили следующий результат:

Давайте посмотрим, приемлемое ли это количество пользователей для взятого нами числа копий конфигураций, равного 4. Для данного развёртывания используем группы обеспечения доступности баз данных (англ. Database Availability Group, или DAG) с 16 узлами, чтобы воспользоваться в полной мере масштабируемостью и доступными преимуществами больших DAG. Хотя мы имеем большое количество доступных дисковых накопителей на выбранной аппаратной платформе, мы ограничены максимальным количеством копий баз данных на сервере Exchange 2013, равным 50. Учитывая этот «максимум» и желание иметь по 4 базы данных на томе, вычислим максимальное число дисковых накопителей баз данных почтовых ящиков.Учитывая полученное значение, можно рассчитать максимальное количество пользователей на одну базу данных (с точки зрения ёмкости системы хранения, данная цифра может измениться после оценки требований ввода-вывода):

Имея 12 томов по 4 копии баз данных на каждом, в общем, получим по 48 копий БД на каждом сервере.

Учитывая количество пользователей для каждой базы данных, равное 66, и общее число пользователей, равное 100 000, вычислим количество DAG для наших пользователей:

При данном очень большом развёртывании используем DAG в качестве единицы масштабирования или «строительного блока» (например, выполним планирование ёмкости системы хранения, основываясь на DAG, необходимых для удовлетворения наших требований, и развернём целый DAG, когда возникнет необходимость в дополнительной ёмкости), поэтому в данном случае нецелесообразно развёртывать неполный DAG. При округлении количества DAG до 8 можно рассчитать окончательное количество пользователей базы данных:

Полученное значение в 65 пользователей на базу данных, означает, что ожидается следующий объём дискового пространства для баз данных почтового ящика:
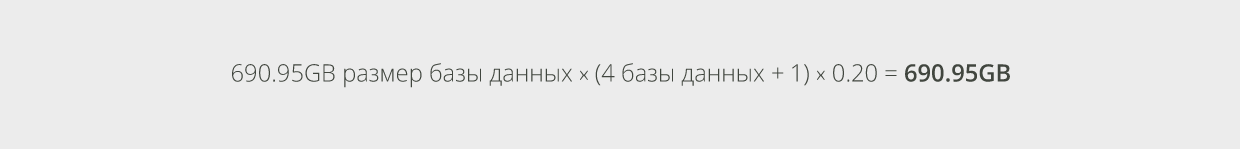
Как вы помните, ранее был рассчитан объём дискового пространства, необходимый для логов транзакций, и неожиданно оказалось, что эти значения были рассчитаны с предположением, что было бы по 65 пользователей на каждую базу данных. Какое приятное совпадение! Таким образом, нам нужно выделить14.53GB дискового пространства для логов транзакций каждой базы данных. Теперь рассчитаем более полезное значение:Воспользуемся формулой, рассмотренной ранее, и рассчитаем приблизительный объём дискового пространства, требуемый для индексации контента:

Подводя итог, оценим общий объём дискового пространства, используемый на томе, и убедимся, что было выделено достаточное количество дисковой памяти, равное 4TB:

Таким образом, был выполнен подбор дискового пространства под базы данных.
4.4 Требования к IOPS
Для постановки требований к количеству операций ввода-вывода в секунду (англ. input/output operations per second или IOPS) базы данных, примем во внимание количество пользователей, зарегистрированных в базе данных, приведённое в таблице 2, с рекомендациями для вычисления общего требуемого IOPS для активного и пассивного состояния базы данных.
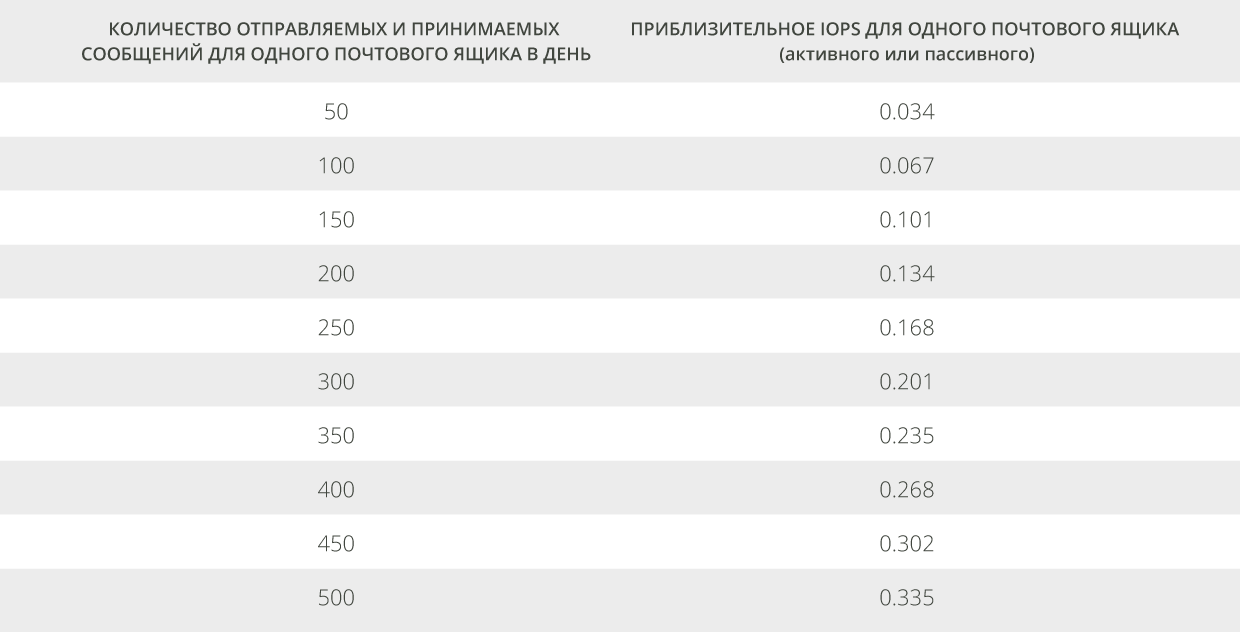 |
|
| Таблица 2. Количество IOPS для одного почтового ящика в зависимости от количества отправляемых и принимаемых сообщений в день |
Например, если количество пользователей базы данных равно 50, а средний профиль сообщений равен 200, ожидается, что база данных потребует 50 * 0.134 = 6.7 транзакционных IOPS, когда база данных активна, и 50 * 0.134 = 6.7 транзакционных IOPS, когда база данных пассивна. Не забудьте решить вопрос о размещении базы данных, которое повлияет на количество баз данных с требованиями IOPS на заданном томе дискового пространства (который может быть как простым JBOD-массивом, так и быть хранилищем сложной конфигурации).
Возвращаясь к рассматриваемому примеру, определим для него требования IOPS. Вспомнив, что средний профиль пользователя в этом развёртывании равен 200 сообщениям в день, и что имеется 65 пользователей базы данных и 4 базы данных на каждом JBOD-диске, определим требования IOPS для худшего случая (когда все базы данных активны) следующим образом:

При этом известно, что диски SAS среднего уровня обеспечивают ~57.5 случайных IOPS.
4.5 Требования к пропускной способности хранилища
Наряду с тем, что обычно требования IOPS – основная проблема пропускной способности хранилища при проектировании решения Exchange, можно столкнуться с ограничениями пропускной способности различных типов сетей хранения. При составлении рекомендаций по вычислению необходимого количества IOPS были рассмотрены транзакционные (в некоторой степени случайные) IOPS и проигнорирована последовательная часть рабочей нагрузки по вводу-выводу. Существует ситуация, при которой последовательные операции ввода/вывода (англ. input/output или IO) становятся проблемой, – это обработка большого количества последовательных IO через общий канал. Наглядным примером загрузки такого типа является непрерывная фоновая поддержка базы данных (называемая в Exchange «background database maintenance» или BDM), работающая непрерывно для баз данных почтовых ящиков Exchange. В то время как эта рабочая нагрузка BDM может быть несущественной для нескольких баз данных, хранящихся на JBOD-диске, она может стать проблемой, когда все тома с базами данных почтовых представлены через общий iSCSI или интерфейс Fibre Channel. В этом случае, пропускная способность общего канала должна быть продумана таким образом, чтобы гарантировать, что он не станет узким местом для таких операций IO.
Для Exchange 2013 ожидается потребление ширины полосы пропускания на уровне примерно в 1Мбит/с для базы данных, что ниже по сравнению с Exchange 2010. В результате сокращения потребления ширины полосы пропускания на одной дисковой полке можно разместить больше почтовых ящиков, а также избежать узких мест при размещении хранилища в сети, например, на iSCSI системе хранения.
4.6 Требования транспорта к объёму хранилища
Поскольку транспортные компоненты (за исключением транспортного front-end компонента для функции CAS) стали частью роли Mailbox, требования центрального процессора и дискового пространства для транспорта (компонент Microsoft Exchange, отвечающий за передачу сообщений, называется транспортом) были включены в список общих требований функционала роли Mailbox, который будет приведён далее. Для корректной работы транспорта необходимо выполнение требований к объёму хранения, связанному с очередями баз данных. Эти требования, также как и описанные ранее требования для дискового пространства под почтовые ящики, состоят из коэффициентов использования ёмкости системы хранения и коэффициентов пропускной способности IO.
Ёмкость системы хранения для транспорта основывается на двух потребностях: формирование очереди (включая теневое формирование очереди) и Safety Net (которая заменяет транспортную корзину в данном релизе). Можно рассчитать требования к ёмкости системы хранения для транспорта как сумму сообщений на диске, включающем, в самом худшем случае, три элемента:
-
Текущий дневной траффик сообщений, наряду с сообщениями, находящимися на диске дольше, чем это установлено в настройках (как пример негативного воздействия очереди сообщений)
-
Сообщения в очереди, ожидающие доставки
-
Сообщения, сохранённые в Safety Net для повторной отправки
Эти факторы появились вследствие теневого формирования очереди, при котором копия, дублирующая все сообщения, сохраняется на другом сервере.
Для расчёта количества сообщений, которое будет ежедневно проходить через систему, необходимо знать количество пользователей, а также профиль отправки/получения сообщений. Перемножив эти значения, можно получить ежедневный объём электронной почты. При этом полученное значение будет немного выше необходимого, так как оно содержит в себе удвоенное количество сообщений, пересылаемых внутри организации (то есть сообщение, отправленное внутри компании, зачтётся как в профиль сотрудника, отправившего его, так и в профиль сотрудника, получившего его, хотя это, в действительности, одно сообщение, перемещающееся по системе). Самый простой способ вычислить ежедневное количество сообщений – проигнорировать этот завышенный параметр транспортировки, который приводит к использованию дополнительной ёмкости хранения, рассчитанной на непредвиденные пики в трафике сообщений. В качестве альтернативного способа определения ежедневного потока сообщений могут быть использованы счётчики производительности внутри существующей системы передачи сообщений.
Для определения максимального размера базы данных очереди примем целую систему за единицу, а затем найдём значение для каждого сервера.


Взяв исходные данные из рассмотренного ранее примера со 100000 пользователей, вычислим размер базы данных очереди.

В рассматриваемом примере имееся 8 DAG, каждый из которых состоит из 16-ти узлов. Спроектируем их таким образом, чтобы система выдержала выход из строя 2-х узлов в любой из DAG. Это означает, что в худшем случае, при возникновении сбоя у нас будет по 112 непрерывно работающих и 2 неисправных сервера в каждой DAG. Воспользуемся полученным значением для определения размера БД очереди на каждом сервере:
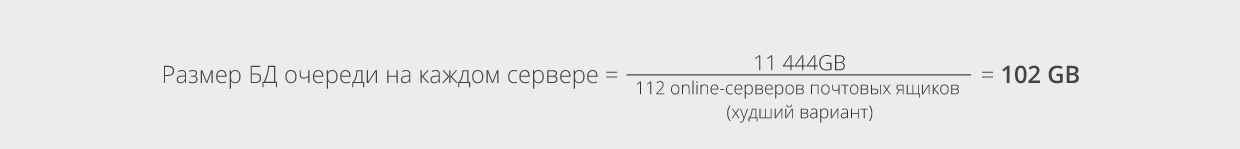
Сайзинг требований пропускной способности транспорта IO легко выполнить. Транспорт открывает большое количество возможностей для уменьшения числа операций ввода-вывода базы данных ESE, которые были добавлены в недавно выпущенных версиях Exchange. Это привело к снижению количества IOPS, требуемых для поддержки транспорта. При составлении данной статьи по сайзингу при внутреннем развёртывании была получена приблизительно 1 операция записи в БД для каждого сообщения и практически ни одной операции чтения из БД при среднем размере сообщений, равном ~75KB. Ожидается, что при увеличении среднего размера сообщений, вырастет и количество транспортных операций ввода/вывода, необходимых для поддержки процессов доставки и формирования очереди. В данный момент нельзя сказать, какой вид будет иметь эта кривая, в этой области проводятся активные исследования. Между тем, можно найти практические рекомендации команды разработчиков для базы данных очереди, поискав их в папке с установочными файлами Exchange (скорее всего, на диске с ОС), и убедиться, что дисковый накопитель, поддерживающий этот путь к каталогу, использует защищённый контроллер кэширования записи на диск, установив 100% кэширования записи, если контроллер позволит оптимизацию настроек кэширования чтения/записи. Кэширование записи позволяет журналу транзакций IO базы данных очереди стать более «свободным» и позволяет транспорту работать с более высокой пропускной способностью.
4.7 Требования к процессору
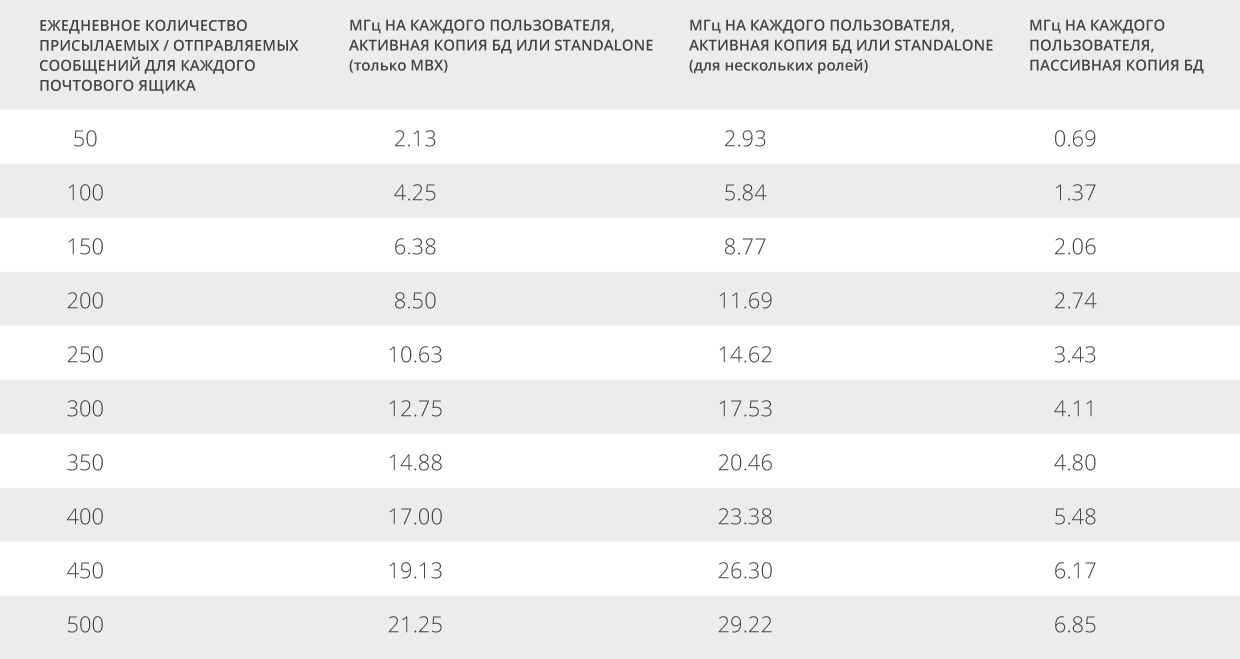
После определения объёма необходимого дискового пространства вычислим необходимые характеристики процессора. Сайзинг процессора для инсталляции роли Mailbox выполним в мегагерцах (МГц). Мегагерц – это единица измерения работы процессора, равная 1 миллиону герц. Проще говоря, процессор выполняет один миллион операций в секунду. Учитывая рекомендации по необходимому количеству МГц, которые приведены ниже для активных и пассивных пользователей во время пиковых нагрузок, можно определить конфигурации процессора, требуемые для рабочих нагрузок Exchange. В таблице 3 приведены рекомендации по количеству МГц для различных профилей пользователя:
 |
|||
| Таблица 3. Рекомендации по количеству МГц для различных профилей пользователя |
Во втором столбце представлено вычисленное количество мегагерц для роли почтового сервера, на котором располагается активная копия базы данных почтового ящика. В конфигурации DAG требуемое число МГц на каждого пользователя для каждого сервера, на котором расположена пассивная копия базы данных почтового ящика, приведено в четвёртом столбце. Если выбранное решение включает в себя многоцелевые сервера (Mailbox+CAS), следует использовать значения, приведённые в третьем столбце, так как они включают дополнительные требования к процессору для роли CAS.
Важно отметить, что если много лет назад можно было предположить, что процессор с 500 МГц мог выполнить примерно в два раза большее количество операций, чем процессор с 250 МГц, то сейчас тактовая частота больше не является надёжным показателем. Внутренняя архитектура современных процессоров сильно различается в зависимости от производителя и даже в пределах производственных серий одного производителя, что требует дополнительных мер по стандартизации для определения доступной вычислительной мощности конкретного процессора. Рекомендуется воспользоваться оценкой на соответствие образцам SPECint_rate2006, разработанной организацией Standard Performance Evaluation Corporation (SPEC).
За базовую конфигурацию при написании данной статьи был принят сервер Hewlett-Packard DL380p Gen8, включающий в себя процессоры Intel Xeon E5-2650 2 GHz. Базовая конфигурация по оценке SPECint_rate2006 составляет 540 единиц, или 33.75 на каждое ядро, учитывая, что протестированный на соответствие образцам сервер комплектовался в общей сложности 16-ядерным физическим процессором. Обратите внимание, что данная базовая конфигурация отличается от той, которая использовалась в рекомендациях к сайзингу Exchange 2010, то есть любые инструменты или калькуляторы, которые были разработаны для базовой конфигурации 2010, не дадут точные результаты для сайзинга Exchange 2013.
Определим предполагаемую доступную рабочую нагрузку Exchange в МГц, обеспечиваемую разными процессорами следующим образом:
-
Найдите оценку SPECint_rate2006 для процессора, который вы намереваетесь использовать для вашей системы Exchange. Это можно сделать собственноручно (описанным ниже способом) или воспользоваться хорошим инструментом по вопросам выбора процессора (Processor Query Tool) Александра Скотта (Scott Alexander), чтобы определить точные характеристики каждого сервера, а также количество ядер процессора для вашей аппаратной платформы.
a. На сайте организации Standard Performance Evaluation Corporation выберите Results, выделите CPU2006, а затем выберите Search all SPECint_rate2006 results.
b. Под Simple Request введите критерии поиска, соответствующие вашему процессору, например Processor Matches E5-2630.
c. Найдите конфигурации сервера и процессора, в использовании которых вы заинтересованы (в случае, если точное соответствие не найдено, выберите максимально близкое к нему) и запишите эти значения в столбцы Result и # Cores.
-
Получите оценку SPECint_rate2006 для каждого ядра, разделив значение столбца Result на значение столбца # Cores. Для примера с сервером Hewlett-Packard DL380p Gen8, который имеет процессоры Intel Xeon E5-2630 (2.3 GHz), значение столбца Result равно 430, а значение столбца # Cores – 12, то есть значение для каждого ядра было бы равно 430/12 = 35.83.
-
Определите предполагаемые доступные МГц рабочей нагрузки Exchange на целевой аппаратной платформе, воспользовавшись следующей формулой:

Для примера с платформой Hewlett-Packard, содержащей процессора E5-2630, который был рассмотрен ранее, был бы получен следующий результат:

Следует иметь в виду, что хорошее планирование работы Exchange никогда не должно предполагать использование сервера на все 100% мощности процессора. В целом, использование процессора на 80% при отказах – это разумный план для большинства пользователей. Учитывая тот нюанс, что наиболее интенсивное использование процессора происходит во время отказов, можем сказать, что сервера имеющие высокую доступность для системы Exchange, при нормальном функционировании будут работать с относительно низкой нагрузкой на процессор. Кроме того, могут возникнуть серьёзные основания выставить в качестве максимума более низкое использование процессора, особенно в случаях, когда непредвиденные всплески в нагрузке могут привести к острым вопросам относительно ёмкости хранения.
Возвращаясь к предыдущему примеру, в котором 100 000 пользователей и профиль пользователя, равный 200 сообщениям, оценим общее количество требуемых мегагерц для развёртывания. Известно, что в развёртывании будет 4 копии базы данных. Это поможет вычислить количество требуемых пассивных мегагерц. Предположим, что данное развёртывание будет использовать сервера с множеством ролей (Mailbox+CAS). Учитывая эту информацию, рассчитаем требуемое количество мегагерц следующим образом:

Возьмите это число и попытайтесь определить необходимое количество серверов. Намного лучше будет подобрать количество серверов, исходя из высоких требований доступности (приняв во внимание, какое количество отказов компонентов ваш проект может обработать, чтобы ответить бизнес-требованиям), и затем убедиться, что эти сервера соответствуют требованиям к процессорам для самого худшего случая. Ваш сервер или будет соответствовать требованиям к процессору без каких-либо изменений (если количество ваших серверов связано с другим аспектом процесса сайзинга), или вам придётся регулировать количество серверов (горизонтальное расширение – scale out) или настроить спецификации сервера (вертикальное расширение – scale up).
Продолжим рассмотрение нашего гипотетического примера. Так как было предположено, что высокие требования доступности для примера проекта с 100 000 пользователей приведут к тому, что максимум 16 из 48 баз данных могут быть одновременно активными на каждом сервере, и каждая база данных имеет по 65 пользователей, определим требования к процессору каждого сервера для развёртывания.

Воспользуемся упомянутой конфигурацией процессора в разделе нормализации МГц (Е5-2630 2.3 GHz процессоры на сервере HP DL380p Gen8), и тем, что у нас есть 25,479 доступных МГц на сервере, и вычислим среднюю пиковую нагрузку процессора в самом худшем случае отказов как:
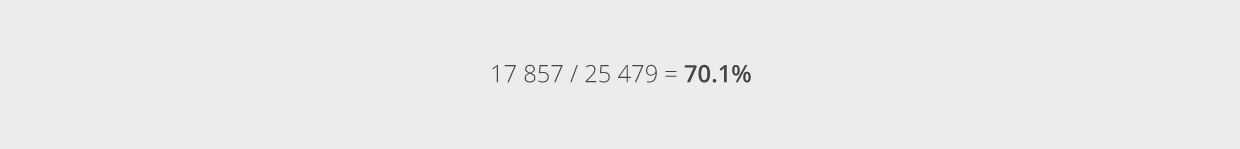
Полученное значение меньше максимального процента использования процессора в самом худшем случае. Таким образом, в данном проекте не нужно соединять сервера для использования большего числа процессоров. Фактически, можно было бы рассмотреть более дешёвый вариант процессора с меньшей производительностью, что приблизило бы нас к средней пиковой нагрузке в 80% для самого худшего случая и позволило бы уменьшить общую стоимость системы.
4.8 Требования к памяти
Для вычисления памяти каждого сервера необходимо знать количество пользователей на один сервер (и активных, и пассивных пользователей), а также определиться: будете ли вы использовать роль Mailbox изолированно или развернёте сервера с множеством ролей (Mailbox+CAS). Учтите, что независимо от того, развернёте ли вы роли изолированно или развернёте сервера с множеством ролей, минимальное количество RAM для любого из серверов Exchange 2013 составляет 8GB.
Память для роли Mailbox используется для выполнения многих целей. Как и в предыдущих релизах, значительное количество памяти используется под кэш базы данных ESE и играет важную роль в сокращении количества операций чтения-записи на диск для Exchange 2013. Новая технология индексирования содержимого, реализованная в Exchange 2013, также использует большое количество памяти. Крупными потребителями памяти остались различные сервисы Exchange, предоставляющие для конечных пользователей транзакционные сервисы или управляющие фоновой обработкой данных. В то время, когда каждый из этих сервисов может не использовать существенное количество памяти, для одновременной работы сервисов Exchange может потребоваться довольно большое её количество.
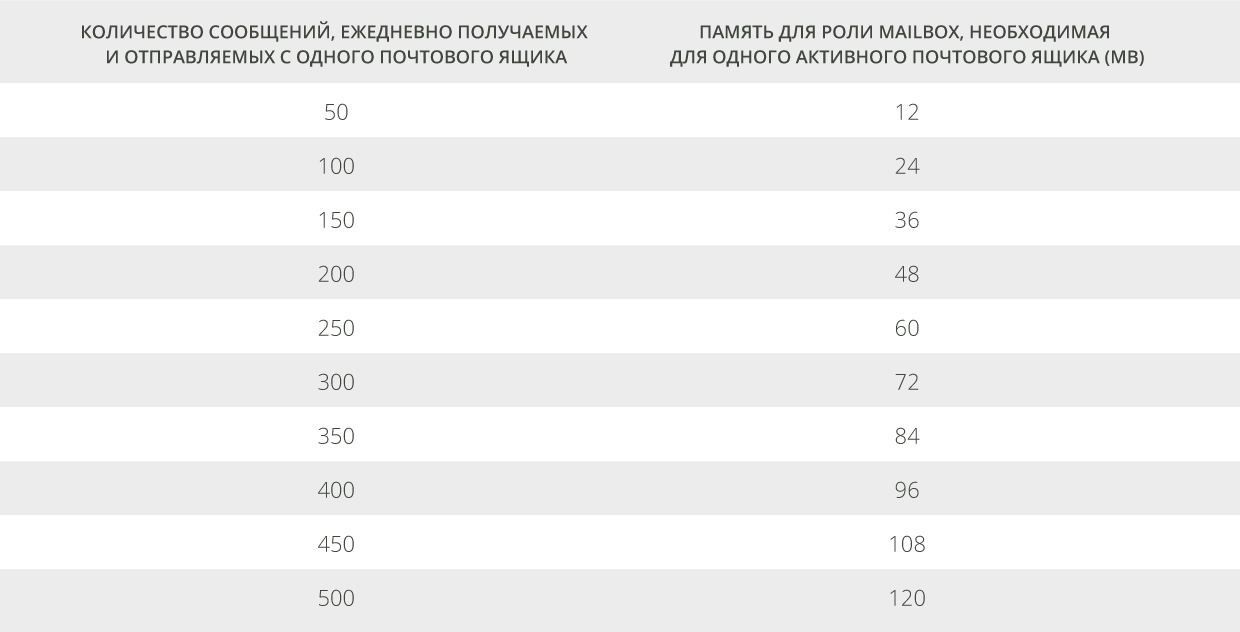
Ниже приведены рекомендации относительно количества памяти для инсталляции в виде роли Mailbox для одного почтового ящика, которое будет необходимо для работы во время пиковых нагрузок.
 |
|
| Таблица 4. Рекомендуемая память для роли Mailbox, необходимая для одного активного почтового ящика |
Для определения необходимого количества памяти сервера, перемножьте число активных почтовых ящиков сервера для самого худшего сценария отказов и значение, соответствующее ожидаемому профилю пользователя. Округлите полученное значение исходя из перспектив закупок (то есть, возможно, будет дешевле сконфигурировать 128GB RAM, чем меньшее количество памяти в зависимости от опций слотов и цены на модули памяти).

Например, для сервера с 48 копиями баз данных (16 активных в самом худшем случае отказов), 65 пользователей на каждую базу данных, ожидаемый профиль пользователя в 200 сообщений в день, мы можем рекомендовать:

Отметим, что технология индексирования содержимого, реализованная в Exchange 2013, использует относительно большое количество памяти для обеспечения быстрого индексирования и быстрой обработки запросов. Использование этой памяти увеличивается с количеством проиндексированных объектов, что означает увеличение общего количества сообщений, сохранённых на сервере в роли Mailbox (и для активных, и для пассивных копий), а также повышаются требования к памяти, необходимой для процесса индексирования содержимого. В целом, представленные в этой статье рекомендации по сайзингу памяти предполагают, что приблизительно 15% памяти системы будет доступно для процесса индексирования содержимого. Это означает, что имея средний размер сообщений, равный 75 КВ, можно разместить почтовые ящики размерами от 3GB для пользователей с профилем в 50 сообщений/день, вплоть до 32GB – с профилем в 500 сообщений/день, не корректируя объём памяти. Если ваше развёртывание будет иметь очень маленький средний размер сообщений или очень большой средний размер почтового ящика, вам, возможно, понадобится дополнительная память, чтобы обеспечить процесс индексирования содержимого.
Для развёртывания сервера с множеством ролей, кроме определённых выше требований, потребуется дополнительную память. Память для CAS вычисляется так: основные требования к памяти для компонентов CAS (2GB) плюс дополнительная память, количество которой определяется из ожидаемой рабочей нагрузки. Общее количество памяти для CAS на многоролевых серверах может быть вычислено с помощью следующей формулы:

По существу, это – 2GB памяти на основные требования, плюс 2GB памяти на каждое ядро процессора (или часть ядра процессора) для использования её во время пиковых нагрузок в самом худшем варианте появления отказов в системе. Обратимся снова к нашему примеру, где имеется 16 активных баз данных на каждом сервере в худшем случае появления отказов и процессор с 2123 МГц на каждое ядро. В таком случае нам необходимо:
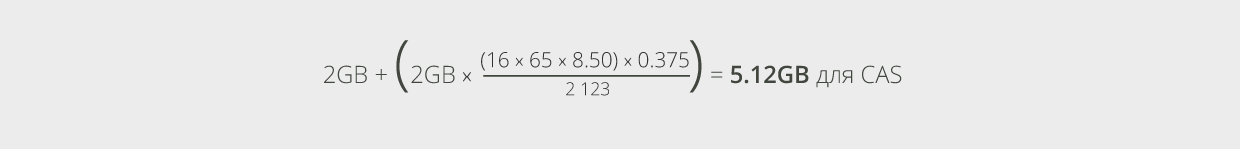
Если добавим полученное значение к вычисленному выше количеству памяти для роли Mailbox, то общее количество памяти для сервера с множеством ролей будет равно:
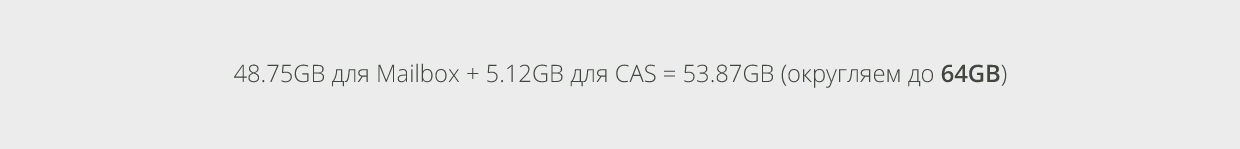
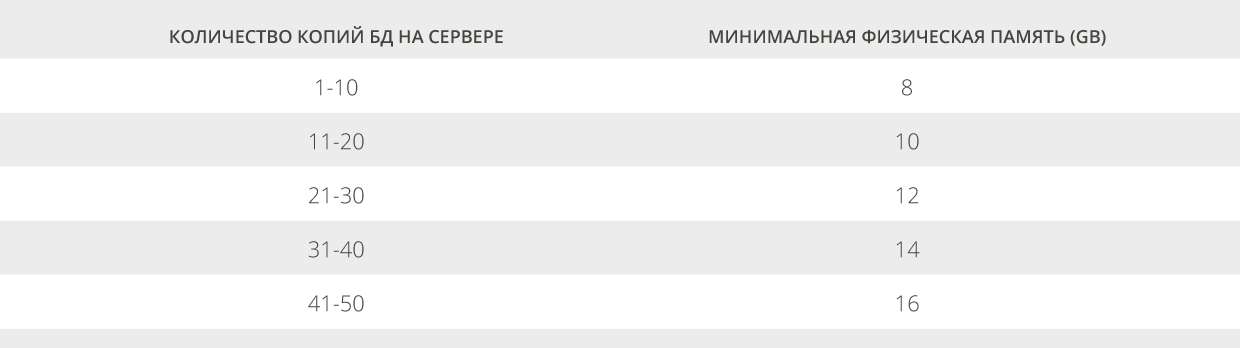
Независимо от того, рассматриваете ли вы многоролевое развёртывание или развёртывание с разделением ролей, важно убедиться, что на сервере есть минимальное количество памяти для эффективного использования кэша баз данных. Существует несколько вариантов, при которых необходимо будет иметь относительно небольшое количество памяти из расчётов, описанных выше. Рекомендуется провести сравнение рассчитанного вами количества памяти, необходимого для каждого сервера, с таблицей 5, чтобы удостовериться, что вы получили минимальное количество памяти для обеспечения кэша баз данных. Данная статья основана на общем количестве копий баз данных (и активных, и пассивных). Если значение, представленное в таблице 5 выше полученного вами, скорректируйте требования к памяти сервера так, чтобы оно соответствовало минимальному значению, приведённому в таблице 5.
 |
|
| Таблица 5. Рекомендации по объёму минимальной физической памяти |
В нашем примере разворачиваем 48 копий баз данных на каждом сервере. Таким образом, минимальное количество физической памяти для обеспечения необходимого кэша базы данных составит 16GB. Так как вычисленное количество памяти, основанное на рекомендациях в расчёте на одного пользователя, включая память для роли CAS, равняется 53.87GB и это больше, чем минимальное количество памяти, равное 16 GB, нам не нужно проводить никаких других корректировок для обеспечения кэша базы данных.
5. Служба Unified messaging
В новой архитектуре Exchange, служба Unified messaging (сокр. UM) уже установлена и готова к использованию на каждом Mailbox и CAS. Предоставленные здесь рекомендации по подбору процессора и памяти предполагают уменьшение использования службы UM. При развёртывании, которое предусматривает значительное использованием службы UM с очень высоким количеством «concurrent call» (параллельных вызовов), возможно, понадобится выполнить дополнительные работы по оценке потребности в аппаратных ресурсах для обеспечения наилучшей доступности для использования. Также как и для Exchange 2010, рекомендуется установить значение параметра «concurrent call», равное 100, в качестве максимально возможного значения «concurrency» службы UM, и масштабировать развёртывание горизонтально в случае, если рабочая нагрузка в вашей среде начнёт приближаться к этому значению. Кроме этого, во время записи голосовой почты очень интенсивно используется процессор и, благодаря выбранному проекту будет только транскрибировать сообщения в то время, как будет достаточно доступной мощности процессора на машине. Во время выполнения транскрипции каждое голосовое сообщение требует 1 ядро процессора, и, если данное количество ядер процессора не может быть удовлетворено, транскрипция будет пропущена. При развёртываниях, где ожидается высокое использование совместных ресурсов (concurrency) процессами транскрипции голосовой почты, конфигурация сервера должна быть скорректирована таким образом, чтобы увеличить ресурсы процессора, или же, возможно, уменьшить количество пользователей сервера, чтобы обеспечить большую доступность процессора для выполнения транскрипции голосовых сообщений.
6. Сайзинг и определение норм роли Client Access Server
В случае, если вы собираетесь расположить роли Mailbox и CAS на разных серверах, процесс сайзинга CAS выглядит довольно просто. Сайзинг CAS, прежде всего, сосредоточен на требованиях, предъявляемых к процессору и памяти. Существует несколько операций ввода-вывода для задач протоколирования, но они несущественны, чтобы составлять отдельное руководство по сайзингу для роли CAS.
Требования к процессору для CAS определяются в соотношении с Mailbox к процессору для роли Mailbox. А именно, необходимо взять 37.5% от мегагерц, используемых для поддержки активных пользователей роли Mailbox. Можно представить необходимое значение как соотношение 3:8 (процессор CAS к процессору активного Mailbox) по сравнению с соотношением 3:4, которое рекомендуется для Exchange 2010. Один из способов расчёта данного значения состоит в вычислении общего количества требуемых мегагерц в расчёте на одного пользователя системы, затем найдите 37.5% от этого значения и определите необходимое количество серверов CAS на основе высоких требований доступности и ограничений при проектировании множества площадок. Рассчитаем данное значение для примера со 100 000 пользователями, использующими профиль в 200 сообщений:
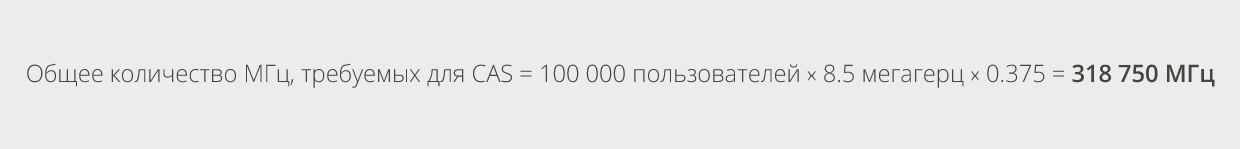
Предположим, что мы хотим использовать процессор на максимально возможные 80%, а сервера, которые хотим развернуть, имеют по 25,479 доступных мегагерц. Таким образом, можно довольно легко вычислить требуемое количество серверов:

Очевидно, что необходимо было бы рассмотреть, соответствуют ли все необходимые 16 серверов высоким требованиям доступности с учётом максимального количества отказов серверов CAS, которое нужно определить, учитывая бизнес-требования, также, как и конфигурацию площадки, поскольку некоторые из серверов CAS могут находиться на разных площадках, управляющих различными частями рабочей нагрузки. Так как для нашего примера было определено, что хотим выдержать двойное количество отказов на одной площадке, увеличим количество наших CAS с 16 до 18. Таким образом, можно обеспечить обработку рабочей нагрузки в случае 2-х отказов CAS.
Для подбора необходимого количества памяти, воспользуемся следующей формулой, аналогичной для системы Exchange 2010:
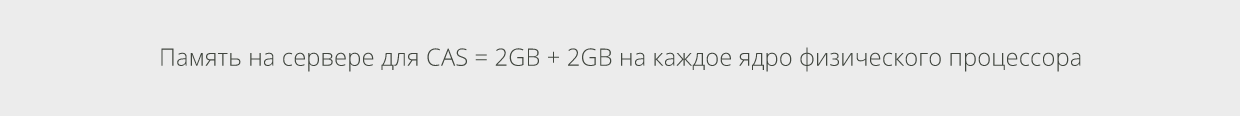


В приведённом примере, 20.77GB – это требуемое количество памяти для CAS. Округлите его до следующей максимально возможной (или самой высокой из представленных) конфигурации памяти для серверной платформы: скорее всего до 24 GB.
7. Объём Active Directory для Exchange 2013
Сайзинг Active Directory остался таким же, как и для Exchange 2010. Для Exchange 2013 рекомендуется провести развёртывание в соотношении «1 ядро процессора для Active Directory глобального каталога к каждым 8 ядрам процессора роли Mailbox, обрабатывающих активные нагрузки», имея в виду 64-разрядные сервера глобального каталога (англ. global catalog, или GC):

Легко можно вычислить необходимое количество ядер, требуемых для GC, для нашего примера:
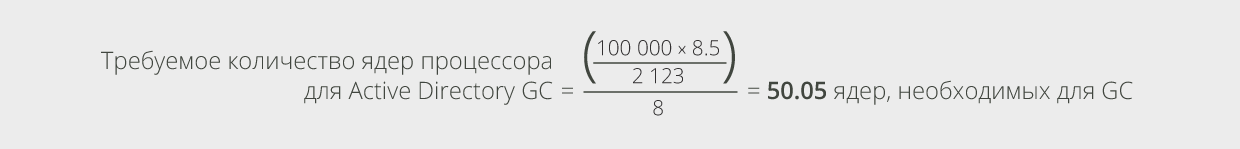
Предположим, что глобальные каталоги Active Directory развёрнуты на такой же аппаратной конфигурации сервера, что и сервера ролей CAS и Mailbox для нашего примера с 12 ядрами процессора, тогда расчёт количества серверов для GC будет выглядеть следующим образом:
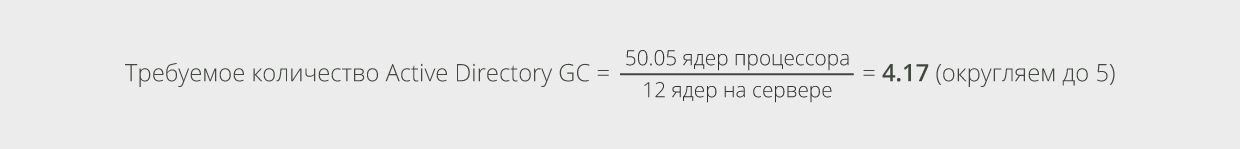
Чтобы обеспечить двойную отказоустойчивость, нужно добавить к полученному значению ещё 2 GC. В итоге получим 7 серверов GC для развёртывания.
Сайзинг памяти на серверах глобального каталога рекомендуется таким образом, чтобы весь файл базы данных NTDS.DIT содержался в RAM. Это обеспечит оптимальное выполнение запросов и лучшие впечатления для конечного пользователя от рабочих нагрузок Exchange.
8. Технология HyperThreading: Вау, свободные процессоры!
Выключите её. Тогда как современные реализации одновременной многопоточности (англ. simultaneous multithreading или SMT), также называемые гиперпоточностью или гиперпоточной технологией (англ. hyperthreading), безусловно, могут повысить производительность процессора для большинства приложений, выгоды от использования его в системе Exchange 2013 не перевешивают оказываемое негативное влияние. Оказывается, возникает значительное влияние на использование памяти серверами Exchange в то время, когда гиперпоточность включена методом, которым сборщик мусора (англ. garbage collector) на сервере .NET резервирует память для дальнейшего её использования. Во время запуска приложения garbage collector на сервере смотрит на общее число логических процессоров и резервирует память для каждого из них. Это означает, что при запуске одной из наших служб, использующих garbage collector на сервере, понадобится почти в два раза большее количество памяти для гиперпоточности, когда garbage collector включена, по сравнению с тем, когда она выключена. Это значительное увеличение использования памяти вместе с анализом реального увеличения производительности процессора для рабочих нагрузок Exchange 2013, возникшее при внутреннем лабораторном тестировании, позволило сделать следующий вывод: гиперпоточность для серверов Exchange 2013 должна быть отключена. Выгоды от использования не перевешивают оказываемое негативное влияние.
Для пользователей, которые виртуализируют Exchange, существует важный нюанс к сделанному выводу. Так как количество логических процессоров, видимых для виртуальной машины, определяется количеством виртуальных процессоров, расположенных в конфигурации виртуальной машины, гиперпоточность не окажет описанного выше влияния на использование памяти. Поэтому, приемлемо сделать доступной гиперпоточность на физическом аппаратном обеспечении, на котором расположены виртуальные машины Exchange. Однако убедитесь, что любые расчёты по планированию ёмкости хранения для этого аппаратного обеспечения основаны исключительно на физических процессорах. Следуйте практическим рекомендациям производителей гиперпоточной технологии, чтобы решить сделать ли доступной гиперпоточность. Обратите внимание, что дополнительные логические процессоры, которые добавляются в случае, когда гиперпоточность включена, не должны учитываться при распределении ресурсов виртуальной машины во время сайзинга и развёртывания. Например, на физическом хосте, на котором работает система Hyper-V с 40 ядрами физических процессоров и включена гиперпоточность, операционная система будет видеть 80 ядер логических процессоров. Если ваш проект Exchange требует сервера с 16-тью ядрами процессора, вы могли бы разместить 2 виртуальные машины Exchange на физическом хосте, поскольку те 2 виртуальные машины использовали бы 32 ядра физических процессоров без достаточного их количества, чтобы разместить на хосте другую виртуальную машину с 16-тью ядрами (32 + 16 = 48, что больше 40).
Редакция Практики
